Il panorama delle automazioni basate sull’intelligenza artificiale sta vivendo una fase di profonda trasformazione. Fino a poco tempo fa, integrare un AI Agent all’interno di un flusso di lavoro significava spesso dover scendere a compromessi tra potenza e costi. Oggi, grazie all’introduzione del Model Selector, questa barriera e stata abbattuta, permettendo di creare sistemi dinamici in grado di scegliere autonomamente il ’motore’ piu adatto per ogni singola operazione.
In questo approfondimento, esploreremo come configurare correttamente questa funzionalita per smistare i compiti in base alla loro effettiva difficolta. Troppo spesso, infatti, si commette l’errore di impiegare modelli estremamente costosi e complessi per rispondere a domande banali o per eseguire compiti di routine. Grazie al Model Selector, e possibile differenziare l’input in modo intelligente: le richieste semplici vengono affidate a modelli rapidi ed economici, mentre solo i task che richiedono una reale capacita di ragionamento vengono inoltrati ai modelli di fascia alta.
Oltre alla pura logica di instradamento, analizzeremo come la scelta dell’infrastruttura possa influenzare le prestazioni complessive delle vostre automazioni. Vedremo perche optare per un VPS rappresenti una soluzione strategica per chi desidera scalare i propri progetti mantenendo il pieno controllo sulle risorse. Preparatevi a scoprire una metodologia di lavoro che non solo velocizza l’esecuzione dei processi, ma rende l’intero ecosistema dell’intelligenza artificiale piu sostenibile e professionale.

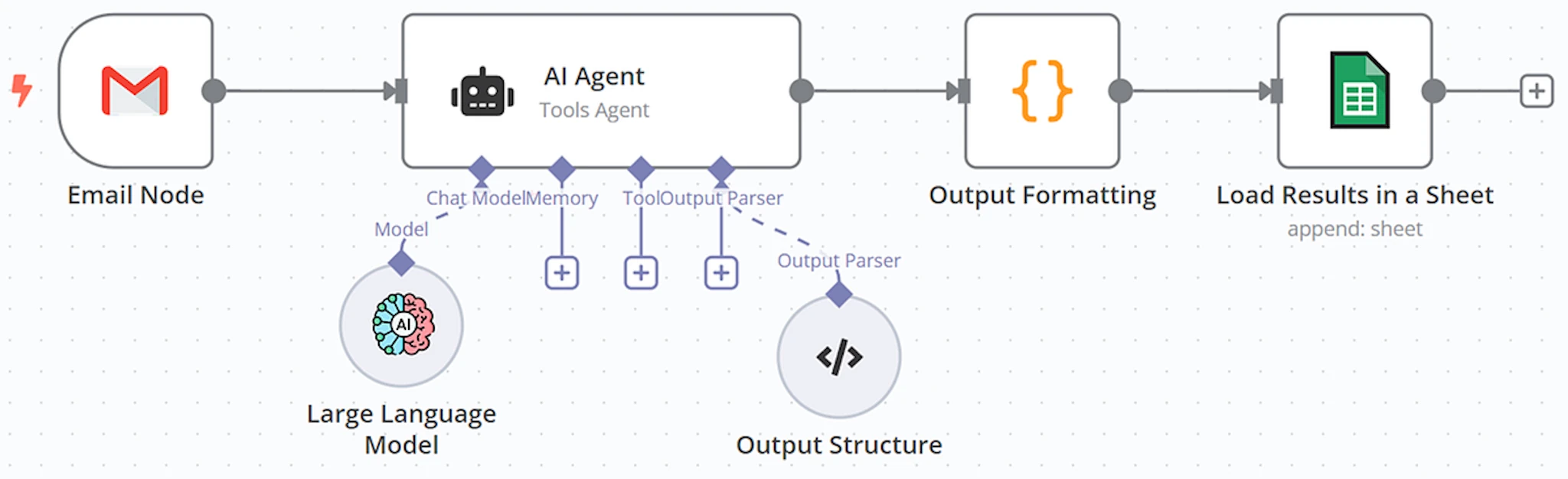
L’evoluzione tecnologica all’interno di n8n ha portato alla creazione di uno strumento che cambia radicalmente le regole del gioco. Il Model Selector non e semplicemente un nuovo nodo, ma un vero e proprio centro di smistamento intelligente per le richieste rivolte ai modelli di linguaggio. Per comprendere la sua portata, dobbiamo pensare a come venivano costruite le automazioni fino a ieri: ogni volta che si integrava un AI Agent, eravamo vincolati a un unico modello predefinito per l’intera durata del workflow.
Questa rigidita strutturale portava a inefficienze croniche. Se l’automazione doveva gestire sia un semplice saluto che un’analisi complessa di dati finanziari, il modello piu potente veniva utilizzato indiscriminatamente per entrambi, con un inutile spreco di risorse. Il Model Selector agisce come un layer di astrazione: invece di collegare un singolo LLM, colleghiamo questo selettore che puo ospitare al suo interno una vasta gamma di modelli differenti, da GPT a Claude, fino alle versioni piu leggere di Gemini.
L’impatto sulla velocita e immediato. I modelli di dimensioni ridotte sono progettati per essere estremamente reattivi. Quando il sistema identifica un compito che non richiede un’elaborazione profonda, il Model Selector attiva istantaneamente la risorsa piu veloce. Questo non solo ottimizza i tempi di risposta dell’automazione, ma garantisce che le risorse piu pregiate e lente siano conservate esclusivamente per i momenti in cui la loro potenza di calcolo e davvero indispensabile.
Inoltre, questa funzionalita permette di superare i limiti dei singoli fornitori. Se un modello specifico riscontra problemi di latenza o downtime, e possibile ridisegnare il flusso per spostare il carico su un’altra risorsa in pochi clic. In sintesi, il passaggio da un’architettura a modello singolo a una multi-modello guidata dal Model Selector rappresenta il passo fondamentale per chiunque voglia costruire sistemi AI che siano davvero pronti per un utilizzo professionale su larga scala.
La messa in opera di un sistema basato su Model Selector richiede una pianificazione attenta, poiche il nodo da solo non possiede la capacita intrinseca di decidere quale modello usare senza istruzioni precise. Il cuore di questa architettura e il ’classificatore’, un passaggio logico preventivo che analizza la natura del messaggio in entrata. In n8n, questo si traduce spesso nell’inserimento di un nodo AI dedicato esclusivamente alla categorizzazione della richiesta prima che questa raggiunga l’AI Agent principale.
Il segreto di un buon classificatore risiede nel prompt di sistema. Dobbiamo istruire l’intelligenza artificiale a valutare la complessita del testo dell’utente e a restituire un’etichetta univoca. Ad esempio, potremmo stabilire tre categorie: ’Low’ per domande semplici e di cortesia, ’Medium’ per richieste che necessitano di sintesi o estrazione dati, e ’High’ per problemi che richiedono logica avanzata o accesso a strumenti esterni. E vitale che questo nodo di classificazione sia estremamente rapido e configurato per restituire solo la parola chiave necessaria, senza preamboli.
Una volta ottenuta l’etichetta di classificazione, il Model Selector utilizza una logica condizionale per attivare il percorso corrispondente. Se l’output del classificatore e ’Low’, il selettore utilizzeremo un modello estremamente economico come un GPT-3.5 o un Gemini Flash. Se l’output e ’High’, il sistema sblocchera l’accesso al modello ’Latest’ o piu performante disponibile sul mercato. Questo approccio garantisce che l’AI Agent lavori sempre nelle condizioni ottimali, avendo a disposizione la potenza necessaria solo quando serve.
L’utente finale percepira un’esperienza fluida: ricevera risposte istantanee alle domande semplici e risposte meditate e accurate alle sfide complesse. Questo bilanciamento dinamico non solo migliora la percezione della qualita del servizio, ma permette agli sviluppatori di tenere sotto controllo l’utilizzo della memoria e degli strumenti collegati all’agente. La configurazione di un classificatore efficiente e, di fatto, cio che trasforma un semplice bot in un sistema di intelligenza artificiale di classe enterprise.
Per supportare flussi di lavoro complessi che coinvolgono piu modelli di intelligenza artificiale, la stabilita dell’ambiente di hosting diventa un fattore determinante. Sebbene n8n possa essere utilizzato in modalita cloud tramite l’abbonamento ufficiale, molti professionisti preferiscono l’installazione su un VPS (Virtual Private Server). Questa scelta non e dettata solo da ragioni economiche, ma soprattutto dalla necessita di avere il controllo totale sulla configurazione del sistema e sulla gestione dei dati.
Un server dedicato permette di gestire il carico di lavoro in modo piu elastico. Quando un’automazione attiva piu nodi AI contemporaneamente, la richiesta di risorse puo subire dei picchi improvvisi. Un VPS ben configurato garantisce che n8n abbia sempre la memoria e la potenza di processore necessarie per non interrompere i flussi. Inoltre, operare su un proprio server consente di installare container Docker aggiuntivi, database locali o altri strumenti di supporto che possono interagire direttamente con n8n a latenza zero.
Un altro aspetto fondamentale riguarda la sicurezza e la privacy. Gestire le proprie chiavi API e i dati sensibili degli utenti su un’infrastruttura privata riduce drasticamente i rischi legati a piattaforme terze. Molti fornitori di servizi server offrono oggi soluzioni ottimizzate per l’IA, con dischi NVMe ultra-rapidi e una connettivita globale che assicura che le chiamate ai modelli LLM siano le piu veloci possibili. Questo e particolarmente critico quando si utilizzano tecniche di classificazione che richiedono piu passaggi consecutivi.
In definitiva, investire in un ambiente server professionale significa porre delle fondamenta solide per la propria crescita tecnologica. La possibilita di scalare le risorse hardware in base al volume di automazioni gestite permette di non restare mai bloccati da limiti di piano o costi di abbonamento eccessivi. Per chi vuole fare dell’automazione un pilastro del proprio business, l’accoppiata n8n e VPS rappresenta la soluzione piu flessibile, sicura e lungimirante oggi disponibile sul mercato.
L’adozione del Model Selector apre la strada a una gestione dei token incredibilmente oculata, con un impatto diretto sui costi operativi. Consideriamo un caso d’uso reale: un sistema di gestione delle email aziendali. Gran parte dei messaggi in arrivo richiede semplici risposte di conferma o archiviazione. Affidare questi compiti a modelli premium sarebbe un errore finanziario. Il Model Selector, opportunamente configurato, puo gestire il 90% delle interazioni a costi irrisori, riservando il budget solo per quel 10% di email che richiedono un’analisi profonda o una negoziazione complessa.
Un altro esempio calzante riguarda le automazioni per il Content Marketing. Immaginate un flusso che deve generare decine di post per i social media partendo da un articolo di blog. Il compito di estrarre i concetti chiave puo essere svolto da un modello intermedio, mentre la riscrittura creativa con un tono di voce specifico puo essere affidata al modello top di gamma. Questa segmentazione del lavoro permette di ottenere risultati di alta qualita ottimizzando ogni singolo centesimo speso in API.
Non dobbiamo dimenticare le funzionalita di ’Reasoning’. Alcuni dei modelli piu recenti sono eccellenti nel risolvere problemi logici ma molto costosi. Utilizzando il selettore, possiamo decidere di attivare questi modelli solo se il classificatore rileva la presenza di codici di errore, formule matematiche o richieste di debugging. Per tutto il resto della conversazione, il sistema puo continuare a utilizzare modelli piu agili, mantenendo alta la velocita di interazione senza sacrificare l’intelligenza quando serve davvero.
Infine, l’uso del Model Selector permette di sperimentare nuovi modelli appena usciti sul mercato senza dover riscrivere intere automazioni. Basta aggiungere il nuovo modello all’interno del selettore e modificare una singola regola di instradamento per testarne le performance. Questa agilita tecnica e cio che distingue un’azienda capace di innovare costantemente da una che resta prigioniera delle proprie vecchie configurazioni. L’automazione non e piu un processo statico, ma un sistema vivente che si adatta, impara e si ottimizza continuamente.
In questo approfondimento, esploreremo come configurare correttamente questa funzionalita per smistare i compiti in base alla loro effettiva difficolta. Troppo spesso, infatti, si commette l’errore di impiegare modelli estremamente costosi e complessi per rispondere a domande banali o per eseguire compiti di routine. Grazie al Model Selector, e possibile differenziare l’input in modo intelligente: le richieste semplici vengono affidate a modelli rapidi ed economici, mentre solo i task che richiedono una reale capacita di ragionamento vengono inoltrati ai modelli di fascia alta.
Oltre alla pura logica di instradamento, analizzeremo come la scelta dell’infrastruttura possa influenzare le prestazioni complessive delle vostre automazioni. Vedremo perche optare per un VPS rappresenti una soluzione strategica per chi desidera scalare i propri progetti mantenendo il pieno controllo sulle risorse. Preparatevi a scoprire una metodologia di lavoro che non solo velocizza l’esecuzione dei processi, ma rende l’intero ecosistema dell’intelligenza artificiale piu sostenibile e professionale.
Indice
- Come il Model Selector trasforma le automazioni AI
- Strategie di configurazione per un AI Agent multi-modello
- L’importanza di un ambiente server dedicato per n8n
- Applicazioni pratiche e gestione intelligente dei token
Tutorial video
Come il Model Selector trasforma le automazioni AI
L’evoluzione tecnologica all’interno di n8n ha portato alla creazione di uno strumento che cambia radicalmente le regole del gioco. Il Model Selector non e semplicemente un nuovo nodo, ma un vero e proprio centro di smistamento intelligente per le richieste rivolte ai modelli di linguaggio. Per comprendere la sua portata, dobbiamo pensare a come venivano costruite le automazioni fino a ieri: ogni volta che si integrava un AI Agent, eravamo vincolati a un unico modello predefinito per l’intera durata del workflow.
Questa rigidita strutturale portava a inefficienze croniche. Se l’automazione doveva gestire sia un semplice saluto che un’analisi complessa di dati finanziari, il modello piu potente veniva utilizzato indiscriminatamente per entrambi, con un inutile spreco di risorse. Il Model Selector agisce come un layer di astrazione: invece di collegare un singolo LLM, colleghiamo questo selettore che puo ospitare al suo interno una vasta gamma di modelli differenti, da GPT a Claude, fino alle versioni piu leggere di Gemini.
L’impatto sulla velocita e immediato. I modelli di dimensioni ridotte sono progettati per essere estremamente reattivi. Quando il sistema identifica un compito che non richiede un’elaborazione profonda, il Model Selector attiva istantaneamente la risorsa piu veloce. Questo non solo ottimizza i tempi di risposta dell’automazione, ma garantisce che le risorse piu pregiate e lente siano conservate esclusivamente per i momenti in cui la loro potenza di calcolo e davvero indispensabile.
Inoltre, questa funzionalita permette di superare i limiti dei singoli fornitori. Se un modello specifico riscontra problemi di latenza o downtime, e possibile ridisegnare il flusso per spostare il carico su un’altra risorsa in pochi clic. In sintesi, il passaggio da un’architettura a modello singolo a una multi-modello guidata dal Model Selector rappresenta il passo fondamentale per chiunque voglia costruire sistemi AI che siano davvero pronti per un utilizzo professionale su larga scala.
Strategie di configurazione per un AI Agent multi-modello
La messa in opera di un sistema basato su Model Selector richiede una pianificazione attenta, poiche il nodo da solo non possiede la capacita intrinseca di decidere quale modello usare senza istruzioni precise. Il cuore di questa architettura e il ’classificatore’, un passaggio logico preventivo che analizza la natura del messaggio in entrata. In n8n, questo si traduce spesso nell’inserimento di un nodo AI dedicato esclusivamente alla categorizzazione della richiesta prima che questa raggiunga l’AI Agent principale.
Il segreto di un buon classificatore risiede nel prompt di sistema. Dobbiamo istruire l’intelligenza artificiale a valutare la complessita del testo dell’utente e a restituire un’etichetta univoca. Ad esempio, potremmo stabilire tre categorie: ’Low’ per domande semplici e di cortesia, ’Medium’ per richieste che necessitano di sintesi o estrazione dati, e ’High’ per problemi che richiedono logica avanzata o accesso a strumenti esterni. E vitale che questo nodo di classificazione sia estremamente rapido e configurato per restituire solo la parola chiave necessaria, senza preamboli.
Una volta ottenuta l’etichetta di classificazione, il Model Selector utilizza una logica condizionale per attivare il percorso corrispondente. Se l’output del classificatore e ’Low’, il selettore utilizzeremo un modello estremamente economico come un GPT-3.5 o un Gemini Flash. Se l’output e ’High’, il sistema sblocchera l’accesso al modello ’Latest’ o piu performante disponibile sul mercato. Questo approccio garantisce che l’AI Agent lavori sempre nelle condizioni ottimali, avendo a disposizione la potenza necessaria solo quando serve.
L’utente finale percepira un’esperienza fluida: ricevera risposte istantanee alle domande semplici e risposte meditate e accurate alle sfide complesse. Questo bilanciamento dinamico non solo migliora la percezione della qualita del servizio, ma permette agli sviluppatori di tenere sotto controllo l’utilizzo della memoria e degli strumenti collegati all’agente. La configurazione di un classificatore efficiente e, di fatto, cio che trasforma un semplice bot in un sistema di intelligenza artificiale di classe enterprise.
L’importanza di un ambiente server dedicato per n8n
Per supportare flussi di lavoro complessi che coinvolgono piu modelli di intelligenza artificiale, la stabilita dell’ambiente di hosting diventa un fattore determinante. Sebbene n8n possa essere utilizzato in modalita cloud tramite l’abbonamento ufficiale, molti professionisti preferiscono l’installazione su un VPS (Virtual Private Server). Questa scelta non e dettata solo da ragioni economiche, ma soprattutto dalla necessita di avere il controllo totale sulla configurazione del sistema e sulla gestione dei dati.
Un server dedicato permette di gestire il carico di lavoro in modo piu elastico. Quando un’automazione attiva piu nodi AI contemporaneamente, la richiesta di risorse puo subire dei picchi improvvisi. Un VPS ben configurato garantisce che n8n abbia sempre la memoria e la potenza di processore necessarie per non interrompere i flussi. Inoltre, operare su un proprio server consente di installare container Docker aggiuntivi, database locali o altri strumenti di supporto che possono interagire direttamente con n8n a latenza zero.
Un altro aspetto fondamentale riguarda la sicurezza e la privacy. Gestire le proprie chiavi API e i dati sensibili degli utenti su un’infrastruttura privata riduce drasticamente i rischi legati a piattaforme terze. Molti fornitori di servizi server offrono oggi soluzioni ottimizzate per l’IA, con dischi NVMe ultra-rapidi e una connettivita globale che assicura che le chiamate ai modelli LLM siano le piu veloci possibili. Questo e particolarmente critico quando si utilizzano tecniche di classificazione che richiedono piu passaggi consecutivi.
In definitiva, investire in un ambiente server professionale significa porre delle fondamenta solide per la propria crescita tecnologica. La possibilita di scalare le risorse hardware in base al volume di automazioni gestite permette di non restare mai bloccati da limiti di piano o costi di abbonamento eccessivi. Per chi vuole fare dell’automazione un pilastro del proprio business, l’accoppiata n8n e VPS rappresenta la soluzione piu flessibile, sicura e lungimirante oggi disponibile sul mercato.
Applicazioni pratiche e gestione intelligente dei token
L’adozione del Model Selector apre la strada a una gestione dei token incredibilmente oculata, con un impatto diretto sui costi operativi. Consideriamo un caso d’uso reale: un sistema di gestione delle email aziendali. Gran parte dei messaggi in arrivo richiede semplici risposte di conferma o archiviazione. Affidare questi compiti a modelli premium sarebbe un errore finanziario. Il Model Selector, opportunamente configurato, puo gestire il 90% delle interazioni a costi irrisori, riservando il budget solo per quel 10% di email che richiedono un’analisi profonda o una negoziazione complessa.
Un altro esempio calzante riguarda le automazioni per il Content Marketing. Immaginate un flusso che deve generare decine di post per i social media partendo da un articolo di blog. Il compito di estrarre i concetti chiave puo essere svolto da un modello intermedio, mentre la riscrittura creativa con un tono di voce specifico puo essere affidata al modello top di gamma. Questa segmentazione del lavoro permette di ottenere risultati di alta qualita ottimizzando ogni singolo centesimo speso in API.
Non dobbiamo dimenticare le funzionalita di ’Reasoning’. Alcuni dei modelli piu recenti sono eccellenti nel risolvere problemi logici ma molto costosi. Utilizzando il selettore, possiamo decidere di attivare questi modelli solo se il classificatore rileva la presenza di codici di errore, formule matematiche o richieste di debugging. Per tutto il resto della conversazione, il sistema puo continuare a utilizzare modelli piu agili, mantenendo alta la velocita di interazione senza sacrificare l’intelligenza quando serve davvero.
Infine, l’uso del Model Selector permette di sperimentare nuovi modelli appena usciti sul mercato senza dover riscrivere intere automazioni. Basta aggiungere il nuovo modello all’interno del selettore e modificare una singola regola di instradamento per testarne le performance. Questa agilita tecnica e cio che distingue un’azienda capace di innovare costantemente da una che resta prigioniera delle proprie vecchie configurazioni. L’automazione non e piu un processo statico, ma un sistema vivente che si adatta, impara e si ottimizza continuamente.
Salsomaggiore Terme (Web) - 29/04/2026 - Model Selector N8N Rivoluzioniamo le nostre automazioni AI agent
Written by Mokik
Written by Mokik
Link referral
Tuttavia, tenete presente che i link referral non influenzano il nostro giudizio o il contenuto dell’articolo. Il nostro obiettivo è fornire sempre informazioni accurate, approfondite e utili per i nostri lettori. Speriamo che questi link referral non compromettano la vostra esperienza di navigazione e vi invitiamo a continuare a leggere i nostri articoli con fiducia, sapendo che il nostro impegno è offrirvi sempre il meglio.
Amazon Sostieni MrPaloma facendo acquisti su Amazon partendo da questo link amazon.it.
NordVpn Proteggi la tua navigazione e sostienici: acquista NordVPN tramite il link affiliato! Nord Vpn
Amazon Prime | Amazon Music Unlimited | Prime Video | Amazon Business | Kindle Unlimited | Amazon Wedding List | Prime Student